
深入大数据架构师之路系列教程地址:https://www.roncoo.com/view/72
为什么要学习spark,天下武功,唯快不破
运行速度快,开发速度快是Spark最耀眼的特点,Spark号称在磁盘上的运行速度是MapReduce的10倍以上,在内存上的运行速度是MapReduce的100以上;这不仅仅是Spark是基于内存计算,更因为是Spark采用了DAG算法减少了大量的IO开销。
All-In-One的解决方案
谈到Spark,大多数的人首先想到的是内存计算框架,计算速度很快等概念。但对于企业来说,更吸引其眼光的应该是Spark的All-In-One的解决方案。我们来看看Spark Stack: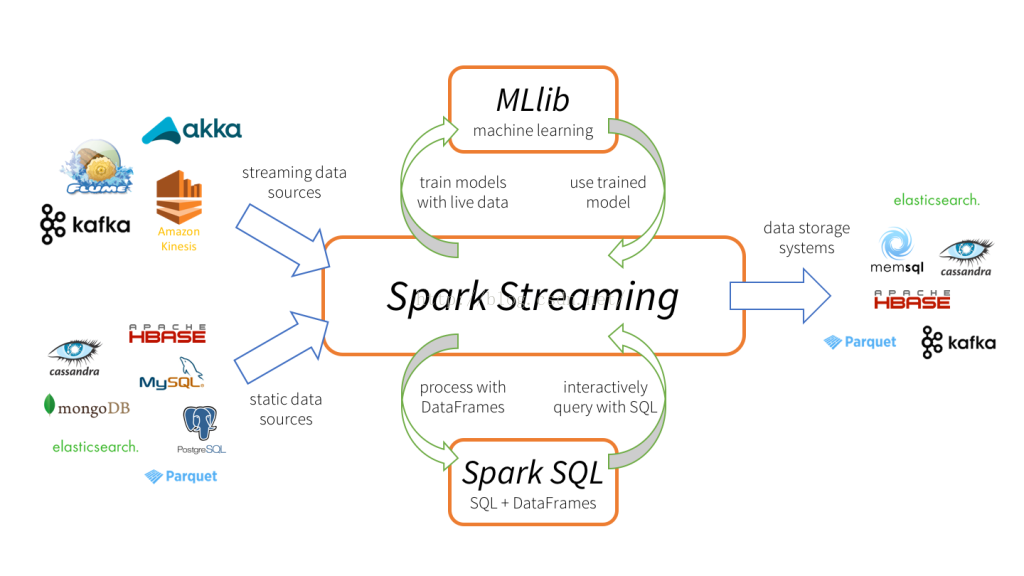
Spark在企业中的应用场景:
应用于离线批处理的Spark RDD、Spark DataFrame
应用于流式计算的Spark Streaming
应用于即席查询(Ad-hoc)的Spark SQL
应用于机器学习(数据挖掘)的MLlib和ml
Spark2.*已经在统一规划上面的各个组件,随着Spark生态的完善和扩展,Spark将能应付各种大数据处理场景。这意味着采用Spark将减少人力和资金的投入,降低的系统的复杂性,减轻维护的工作量
为什么是Python?
市面上的Spark教程和视频,都是用java和scala进行讲解的。为什么要选择python呢?
在人工智能时代, Python 才是编程语言的不二之选。2017 年 9 月 Stack Overflow 发布的统计数据表明是 Python 是增长量最快的编程语言。10 月 GitHub 年度开发者报告中,Python 超过 Java,排在编程语言 Top 15 的第二位。
和java比起来,python有如下优势
1. 异常快捷的开发速度,代码量巨少
2. 丰富的数据处理包,不管正则也好,html解析啦,xml解析啦,用起来非常方便
3. 内部类型使用成本巨低,不需要额外怎么操作(java,c++用个map都很费劲)
4. 绝大多数公司的数据处理工作是不需要面对非常大的数据的
5. 巨大的数据不是语言所能解决的,需要处理数据的框架(hadoop, mpi。。。。)6. 编码问题处理起来太太太方便了,还在坚持用Java做大数据开发,你落伍了。
本课程基于最新的spark 2讲解,内容涵盖了企业中大数据处理的四大场景:
离线批处理
流式计算
SQL处理
机器学习
一门课程就打通python 大数据的任督二脉,意不意外,惊不惊喜!!!小伙伴们,快来加入吧。

- 官方微信

 粤公网安备 44010602005928号
粤公网安备 44010602005928号